

Your "Explainable AI" Requirement Isn't Doing What You Think

Imagine your program office adds “explainable AI” to the requirements document. The vendor’s proposal includes a section on explainability. The evaluators check the box. The contract gets awarded.
Six months later, nobody can tell you why the model flagged that application, denied that claim, or ranked that candidate last. The requirement was listed as “met,” but what if you have to defend the model’s decision in a lawsuit or to Congress?
This is happening constantly. It’s not the vendors’ fault — they gave you exactly what you asked for. Let me help you navigate the buzzword soup and ask for AI that is truly reproducible and explainable.
What Your Contracts Probably Say
Most AI explainability requirements in government contracts look something like this:
“The system shall provide explanations for its outputs that are understandable to end users.”
Most of you reference NIST’s AI Risk Management Framework. Occasionally, people use DARPA’s Explainable AI (XAI) program.
Vendors respond with saliency maps, LIME (Local Interpretable Model-agnostic Explanations), or SHAP (SHapley Additive exPlanations) values. These are real techniques developed by real researchers.
They are also not what you think they are.
A SHAP value tells you which features most influenced a particular prediction. A saliency map highlights which pixels mattered in an image classification. These are useful diagnostic tools. They are not explanations of how the model works or how it arrived at its decisions. There is a significant difference.
Local Interpretable Model-agnostic Explanations (LIME)
Like most government acronyms, LIME sounds like it was named by five people who got trapped in a conference room for five days. Nonetheless, it tries to solve a problem created by black box algorithms (for example: neural network, XGBoost, transformer, ensemble, or eldritch forest spirit). Instead of trying to explain the whole model, LIME is a means to explain ONE prediction of the model at a time.
It does that by approximation. It will say, “Near THIS decision boundary, the model behaves roughly like this simpler thing.” However, that is not an explanation of the actual prediction. Imagine trying to understand a tornado by throwing ping pong balls into it and watching where they fly. You can learn local behavior, directional tendencies, and sensitivity. You are not uncovering the true internal structure of the tornado or the complete causal chain.
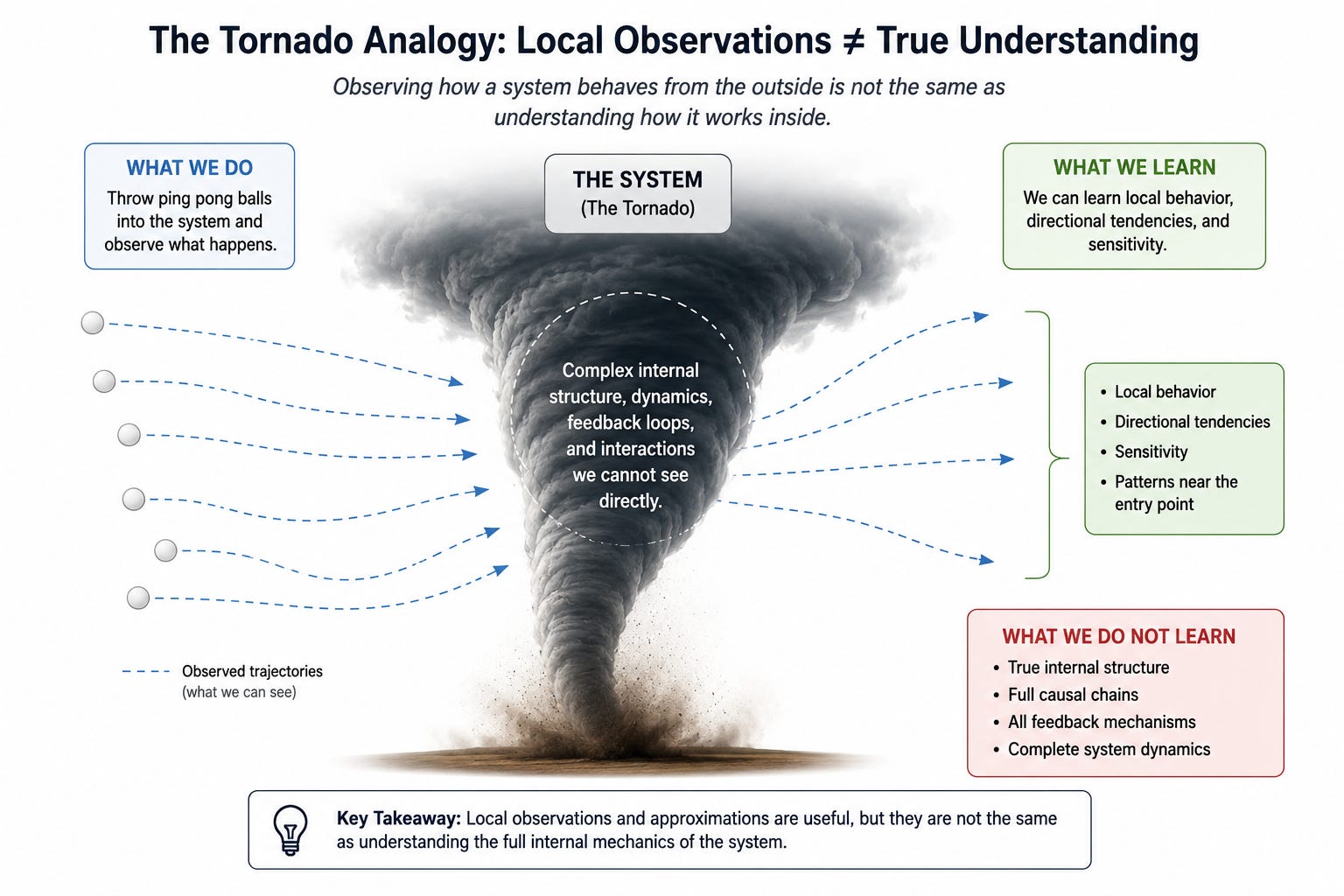
In other words, it answers a different question than what is asked. It answers “What variables affected the output?” instead of “How did the system internally compute this result?” Mechanistic interpretability is not addressed by LIME.
SHapley Additive exPlanations (SHAP)
SHAP comes from cooperative game theory, specifically from Lloyd Shapley’s 1953 work on fairly distributing payouts among players who contributed to a collective outcome. The core idea is elegant: if several players cooperated to win a game, how do you fairly credit each one? SHAP borrows this math and applies it to features in a model. Instead of players dividing winnings, you have input variables dividing responsibility for a prediction.
This sounds more rigorous than LIME, and in some ways it is.

SHAP values have mathematical guarantees that LIME doesn’t. They are consistent, locally accurate, and they sum to the difference between the prediction and the baseline. That’s genuinely useful.
Here’s the problem: SHAP tells you how much each feature contributed to a prediction. It does not tell you how the model used that feature internally. It’s the difference between knowing that a witness was present at a crime scene versus understanding exactly what happened inside the building.
If your model is wrong (and all models are wrong sometimes), SHAP will explain that wrong decision very clearly and confidently. A beautifully rendered SHAP plot of a wrong prediction is still a wrong prediction. Explainability and correctness are not the same thing, and your contract requirements probably don’t distinguish between them.
It gets worse.
SHAP is mathematically a computation of every possible combination of features. This means the number of features is the exponent in the equation. The more features are in the model, the more computationally expensive SHAP is, until it becomes computationally unfeasible for large deep learning models.
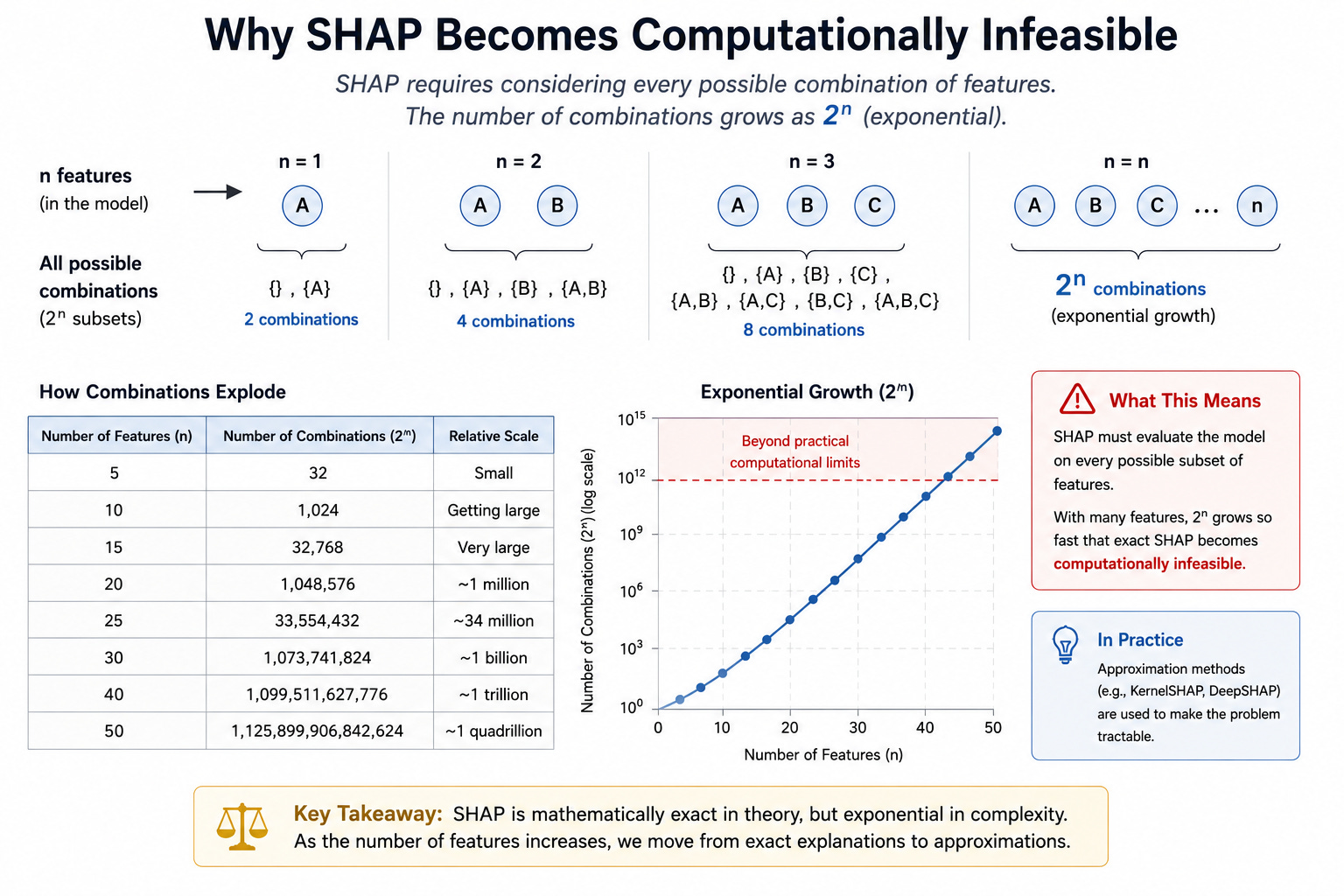
So in practice you don’t get SHAP; you get a flavor of it. Sometimes that’s a sampling approximation like KernelSHAP or DeepSHAP. Sometimes it’s an exact-but-narrow algorithm like TreeSHAP, which only works because it exploits the structure of tree models specifically.
Each variant carries its own assumptions about how features interact, and those assumptions are rarely stated out loud. You are now receiving an approximate explanation of an approximate model making consequential decisions about real people. Your contract said “explainable AI.” What you got was a confidence interval on a guess about a black box.
And here is the part that should concern you most: none of this is disclosed in a typical vendor proposal. The SHAP plots look professional. The colors are nice. The bar charts are sorted. Nothing in the deliverable tells you that the explanation you’re looking at is itself an estimate, computed on a model that nobody fully understands, at a computational cost that made exact values impossible.
You checked the box. The box was the wrong shape.
Other Methods
Gradient-based methods and saliency maps are particularly common in computer vision applications (facial recognition, satellite imagery analysis, or medical imaging). They work by measuring how sensitive the model’s output is to changes in the input. The result is usually a heatmap: a visually compelling image showing which pixels or regions the model “focused on.”
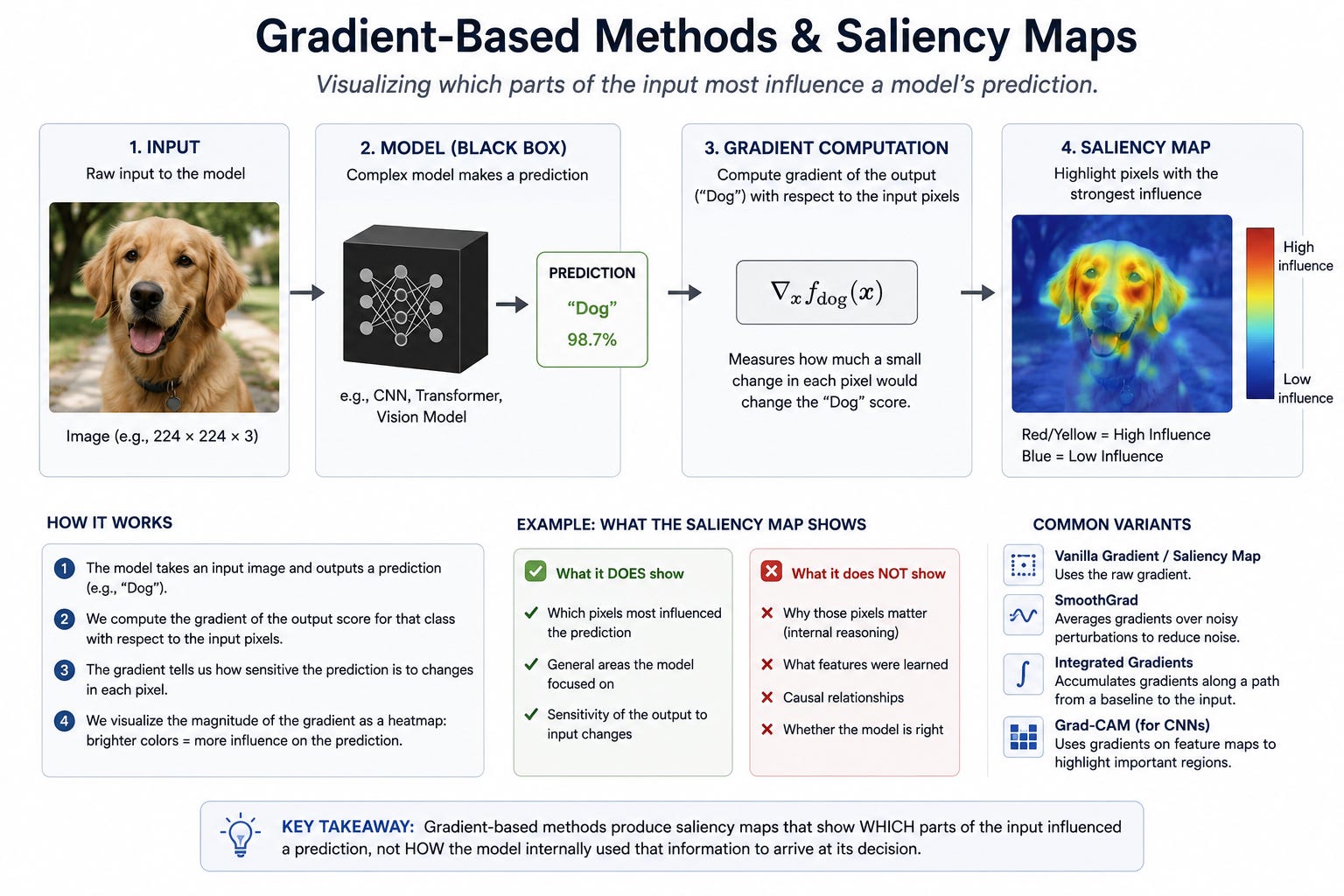
These are the explainability outputs most likely to impress a non-technical evaluator, which is precisely the problem. A heatmap is not a causal explanation. It tells you where the model was sensitive, not why it made the decision it made. A heatmap of a wrongful denial, a missed threat, or a misidentified face looks exactly as professional and colorful as a correct one.
With the explosion of large language model procurement across government agencies, attention weights have become the explainability answer of the moment. Vendors point to attention visualizations (which words or tokens the model “attended to”) as evidence that the system is interpretable.
There is an entire scientific controversy about whether this is true. A 2019 paper by Jain and Wallace titled “Attention is not Explanation” demonstrated that attention weights often do not correlate with other measures of feature importance, and that models can produce the same outputs with very different attention patterns. Attending to something is not the same as deciding because of something. If your LLM procurement includes an explainability requirement satisfied by attention visualizations, you may want to read that paper before your next contract award.
The pattern should be clear by now. Every technique we have discussed answers a different question than the one you are actually asking. Post-hoc explanations describe behavior after the fact. They are not windows into the model’s internal logic, and they do not guarantee that the next similar case will be handled the same way. So what should you actually ask for?
What You Should Ask For
1. Interpretability
First, ask whether the model is inherently interpretable or whether explainability is being applied after the fact. These are fundamentally different things. A logistic regression model, a decision tree, or a rule-based system is interpretable by design. You can follow the math from input to output.
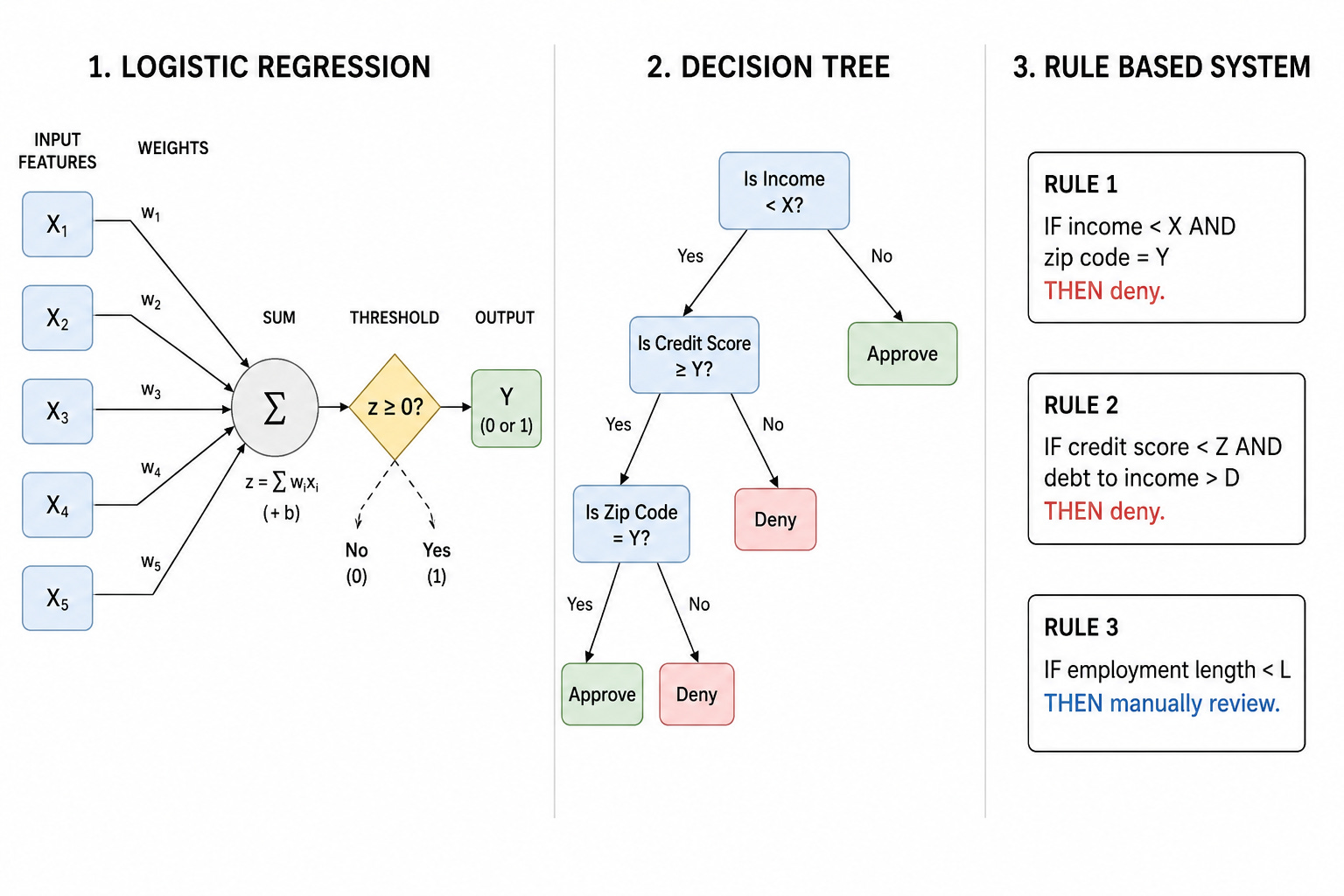
A deep neural network with a SHAP wrapper applied afterward is not. Both can satisfy the language in your current requirements document. Only one actually tells you how the decision was made.
For genuinely black-box use cases (most notably LLMs) inherent interpretability isn’t on the menu, and pretending otherwise is its own kind of dishonesty. There the honest ask is different: documented failure modes, reproducibility where the task allows it, human-in-the-loop for consequential calls, and treating any explanation output as the diagnostic tool it is rather than as accountability.
2. Model Cards
Second, ask for model cards. A model card is a standardized document that describes what a model does, what data it was trained on, where it performs well, and where it fails. Google pioneered the format, and NIST’s AI Risk Management Framework references model cards as a documentation practice. So, a vendor who cannot produce one is a vendor who does not fully understand their own system.
3. Failure Modes
Third, ask about failure modes specifically. “How does this model fail?” is a more useful question than “can you explain this model?” A vendor who can give you a specific, honest answer about failure conditions understands their system. A vendor who responds with a SHAP plot does not.
4. Reproducibility
Fourth, if the application is high stakes (like benefits eligibility, threat assessment, medical decisions, or legal outcomes), ask whether the model’s decisions are reproducible. Given the same input twice, does it produce the same output? If not, why not, and what are the implications for due process? Your vendor should think like a scientist, and scientists’ results are reproducible.
5. Computational Limitations
Finally, require documentation of computational limitations. If SHAP approximations were used, that should be disclosed. If attention weights are being offered as explainability for an LLM, ask specifically what the correlation is between those weights and actual feature importance. Make them show their work.

The Bottom Line
Explainability is not a feature you can bolt onto a black box after the fact and call the requirement met. It is an architectural decision made before the first line of code is written. The techniques your vendors are offering are useful diagnostic tools. They are not substitutes for systems that are interpretable by design.
The good news is that interpretable AI is not a compromise. For many government applications (structured data, eligibility decisions, risk scoring, anomaly detection) inherently interpretable models perform comparably to black box alternatives. You do not have to choose between performance and accountability.
See also: Cynthia Rudin’s 2019 paper, “Stop Explaining Black Box Machine Learning Models for High-Stakes Decisions and Use Interpretable Models Instead” (Nature Machine Intelligence).
Just ask better questions. The checklist above is a starting point. If you would like to discuss what meaningful explainability requirements look like for your specific program, I work on exactly these problems at Jaxorik AI Research Group.
As academic and industry researchers with military experience, we build systems that are interpretable by design, we can show our failure modes, and for high-stakes deterministic decisions, our deployed systems are reproducible.